Something shifted in late March 2026, and if you are working with AI coding tools daily, you probably felt it before you read about it.
The sessions got shorter. The session walls came faster. Developers running Claude Code on a $200/month Max plan reported hitting their rolling 5-hour limits after a handful of prompts. Cursor users started getting unexpected overage charges mid-sprint. Kimi users found their daily message caps evaporating before lunch. Even Google Antigravity, fresh out of preview and promising agentic development workflows, started throwing “model overloaded” errors at inconvenient times.
Welcome to the end of the free lunch.
For about two years, the AI development tools ecosystem operated on a growth-above-all-else model. Companies competed aggressively for developer mindshare by keeping prices low and limits high. The tacit deal was clear: get hooked first, figure out unit economics later. That phase is over.
This is not panic. It is not a collapse. But it is a real inflection point, and the developers who understand what is actually happening will navigate it better than those waiting for things to go back to normal. They won’t.
What Everyone Started Noticing at Once
The discussion broke into the open on Reddit in the last week of March 2026. Threads in r/ClaudeAI, r/ClaudeCode, and r/cursor blew up simultaneously with variations of the same complaint: limits that used to last a workday were now disappearing in an hour.
A thread in r/ClaudeCode titled “Hitting my 5-hour limit in like 20 minutes now - what happened?” accumulated hundreds of upvotes in under 24 hours. The comments were a cross-section of confused paying subscribers, frustrated power users, and developers piecing together what changed. The consensus: something was different, and it was not just one user’s imagination.
The Register picked it up. PCWorld covered it. Forbes ran a piece. Anthropic eventually acknowledged the changes publicly, explaining that they had adjusted 5-hour session limits during weekday peak hours (specifically 5 AM to 11 AM Pacific, or 1 PM to 7 PM GMT) to manage growing demand. They estimated only about 7% of users would be meaningfully affected.
The community’s response to that 7% figure was skeptical. When you filter for developers using Claude Code as a primary tool, the affected percentage looked considerably higher.
Over at r/cursor, a parallel conversation was running. Users on the Pro plan, which had moved toward compute-credit billing the previous year, were reporting that agentic tasks were draining credits at rates that made the $20/month subscription feel inadequate for actual daily coding work. One heavily upvoted thread documented a developer burning through their entire monthly credit allocation in three days while using Agent mode for a refactoring task.
The pattern repeated across tools. Kimi users hit daily message caps earlier than expected. Google Antigravity sessions ended mid-task with capacity errors. GitHub Copilot’s Premium Request quota, already tiered for agent and chat modes, ran dry faster as developers leaned on it for more complex workflows.
This was not coincidence or a bad week. These events reflected a structural shift across the entire AI tooling industry.
The Infrastructure Reality Behind the Limit Walls
To understand why limits are tightening now, you need to understand what it actually costs to run these services.
AI inference, the process of generating model responses, runs on specialized hardware. Specifically, it runs on NVIDIA H100 and H200 GPUs and the newer Blackwell architecture chips. These are not commodity hardware. A single H100 GPU costs between $25,000 and $35,000. A data center rack capable of running frontier-level inference workloads at meaningful scale costs millions. The production lead time for these chips, factoring in NVIDIA’s allocation queues and memory supply chain constraints, has been running between 36 and 52 weeks.
High-Bandwidth Memory (HBM), the specialized memory that makes these GPU chips functional for AI workloads, has been effectively sold out through 2026 according to supply chain analyses from multiple research firms. Memory manufacturers are allocating their HBM production almost entirely to AI datacenter chips because the margins are incomparably better than consumer memory.
The result is an industry-wide compute crunch. Demand for inference capacity is growing exponentially while the physical infrastructure needed to meet it scales in months and years, not weeks.
The “QuitGPT” movement made things noticeably worse for Anthropic specifically. In late February 2026, following OpenAI’s decision to take on a Pentagon contract, approximately 2.5 million users pledged to stop using ChatGPT. A meaningful fraction of them signed up for Claude. This was a significant, sudden demand surge that hit infrastructure with no advance notice. Anthropic could not provision GPU capacity on a two-week timeline. No AI company can.
The session limit adjustments were a pressure valve, not a product decision. When you have more users than compute capacity, you throttle usage during the periods where demand peaks. That is what the weekday peak-hour restrictions represented: real-time demand management on infrastructure that cannot expand fast enough.
Energy compounds the constraint. Data centers running AI inference workloads consume power at densities that conventional air cooling cannot handle. The shift to liquid cooling is already underway industry-wide, but retrofitting or building new facilities takes years. Some reports project that AI workloads could account for close to half of all data center power demand by 2030. Regulatory bodies in multiple countries are already scrutinizing data center power consumption and imposing constraints on site selection and expansion.
The compute crunch is not temporary. The supply chain constraints are real. The infrastructure expansion timelines are real. And every new agentic feature, every tool that lets AI autonomously run code and manage files and loop through multi-step tasks, is dramatically more expensive than a simple chat exchange.
The Agentic Tax Nobody Talked About Clearly
Here is the part that has not been communicated well by any of the major providers, and it is arguably the biggest driver of the “suddenly hitting limits faster” experience.
Agentic usage does not consume proportionally more tokens. It consumes exponentially more.
Consider what happens when you ask Claude Code to “fix the failing tests in my authentication module.” The model does not just respond with text. It reads the test files. It reads the implementation files. It reads the error logs. It potentially reads adjacent modules to understand dependencies. It runs the tests, reads the output, forms a plan, implements changes, and verifies them. Each step in that chain is consuming tokens. The context accumulates throughout the session because the model needs to track what it has done to decide what to do next.
A single agentic coding task that a developer might complete in 30 minutes of interactive prompting could consume 10x the tokens of that same number of standard chat exchanges. The 5-hour session windows that felt ample for conversational AI use are genuinely insufficient for sustained agentic development work.
This was always going to be the case. The AI companies knew it when they priced their plans. The assumption was that agentic usage would remain a fraction of overall use while the ecosystem built up. That assumption turned out to be wrong. Developers adopted agentic tools faster than projected, and the plans that seemed reasonable for chat-heavy use are structurally underpriced for agentic-heavy workflows.
Cursor’s compute credit system acknowledged this more explicitly than most. By moving to usage-based billing, they were implicitly saying: the flat-rate model fails when heavy agentic use costs 10x more than standard use. The problem was that the transition happened faster than users could adapt their expectations, producing bill shock and the Reddit complaints that followed.
The caching bug that affected Claude Code in late March added fuel to the fire. When prompt caching fails or expires, the model re-processes large amounts of context that should have been cached from a previous exchange. Users reported hitting session limits after what felt like two or three prompts, not because of aggressive usage but because a backend caching issue was causing each interaction to cost 5-10x more than it should. Anthropic acknowledged this and shipped fixes, but the incident illustrated how fragile the token economics become when the infrastructure misbehaves.
Tool-By-Tool: Where Everyone Stands

Claude Code and Claude Pro/Max
Anthropic’s limit changes in March 2026 were structured around the 5-hour rolling window. For the Max plan ($100/month lower tier, $200/month higher tier), this had previously felt generous enough for sustained coding work. Post-adjustment, users doing agentic development during weekday peak hours found themselves throttled to a rate that made continuous work impractical.
The practical math: if your 5-hour limit burns roughly twice as fast during peak hours, you have effectively a 2.5-hour functional window for your most common working hours. For developers in US time zones who code during business hours, this directly overlaps with the peak window.
Anthropic’s stated position is that weekly totals remain unchanged, only the distribution across peak versus off-peak periods shifted. Whether that framing is accurate depends on whether you can move your work to off-peak hours, which many professional developers cannot.
The temporary promotion that had doubled usage limits outside peak hours also ended on March 28, making the return to standard limits feel more severe than the raw policy change alone would have.
Google Antigravity
Antigravity is still in public preview, and the “model overloaded” errors it throws represent a different problem than Claude’s strategic limit adjustments. Anthropic is managing capacity intentionally. Google is managing it reactively, because a preview product has not had time to provision infrastructure proportional to its user base growth.
The multi-agent architecture that makes Antigravity interesting (spawning parallel sub-agents to handle different aspects of a task) is also the thing that makes it expensive. Each agent instance is consuming compute independently. If you run five agents simultaneously, you are consuming five instances worth of inference resources. This scales poorly on constrained infrastructure.
Our review of Antigravity flagged these rough edges when it was published, and the capacity issues have not fully resolved as the preview has continued. Google has the infrastructure scale to fix this eventually. The timeline for “eventually” remains unclear.
Cursor
Cursor’s situation is structurally different because they are a layer on top of other providers, primarily Anthropic and OpenAI. When Anthropic raises costs or tightens its own capacity, Cursor absorbs that upstream. Their compute credit billing was designed to pass these costs through to users rather than absorb them as a platform.
The result has been a mismatch between user expectation (a predictable $20/month subscription) and the reality of compute credit consumption during heavy agentic sessions. Cursor has acknowledged the issue and added better spending controls and alerts, but the underlying math has not changed. Complex agentic tasks on frontier models cost more than the flat fee suggests.
The r/cursor community has documented several instances where developers accumulated significant overages during intensive refactoring sessions, discovering the charges after the fact. Cursor’s response has generally been to offer refunds on a case-by-case basis during the transition period while implementing better safeguards.
Kimi Code
Kimi’s situation is technically distinct from Western providers. Moonshot AI built its cost advantage partly through data practices that Western providers have moved away from, and partly through a more aggressive model efficiency focus. The API pricing for Kimi K2.5 sits at $0.60 per million input tokens and $2.50 per million output tokens, compared to Claude Sonnet’s $3.00 and $15.00 respectively. That gap is real.
But Kimi’s free tier daily message limits have still become a point of friction for users who adopted it as a primary tool. When you are generating enough code traffic to hit a daily message cap, you have transitioned from casual user to power user, and the free tier was never sized for power use. The paid tiers remain competitively priced, but the transition from “try this cheap alternative” to “pay for the cheap alternative” is still a friction point that generates complaints.
There is also the data jurisdiction question, which is separate from the limit discussion but relevant to any comprehensive look at the Kimi situation. If you want the full picture on that tradeoff, the Kimi K2.5 API guide covers it in detail.
GitHub Copilot
Copilot’s tiered Premium Request structure has added complexity that was not there when Copilot was a simple autocomplete subscription. The distinction between standard completions (generally unlimited) and premium requests (used for chat, agent mode, and advanced model access) introduces a quota developers only encounter when they try to use the capabilities they are most interested in.
For developers using Copilot primarily as an autocomplete tool, nothing has changed. For developers who have started using agent mode for more complex tasks, the premium request cap becomes a real constraint on their monthly workflow.
Why This Is Not Going Back
The temptation is to frame limit crackdowns as a temporary overcorrection that will normalize once infrastructure catches up. There are reasons to be skeptical of that framing.
First, the infrastructure catch-up timeline is long. Chip supply constraints, energy constraints, and data center construction timelines are all measured in years, not quarters. The demand curve for AI inference is growing faster than the capacity curve, and that gap does not close quickly.
Second, agentic adoption is accelerating, not slowing. Every new use case for AI coding tools, every developer who transitions from casual prompting to genuine agentic workflows, increases the compute requirement per user. The platforms are not getting cheaper to run as users get more sophisticated. The opposite is true.
Third, the business model math requires it. The period of below-cost pricing to acquire users is clearly ending. Anthropic, despite its valuation, is not profitable. OpenAI is not profitable. Google can absorb losses on Antigravity as a strategic investment, but there is a ceiling. The path to sustainable businesses runs through pricing that reflects actual costs, which means less, not more, per-dollar compute than the era of growth-at-all-costs subsidies.
A Stanford analysis from early 2026 noted the structural tension: AI companies have successfully created tools that developers genuinely depend on, which gives them pricing power, but they built that dependency at below-cost pricing levels that cannot persist. The industry is now navigating the transition from the acquisition phase to the monetization phase.
What the Future of AI Pricing Actually Looks Like
There is a reasonable case to be made that usage-based pricing, despite being the source of current friction, is the honest pricing model for this technology. Flat-rate subscriptions obscure the actual cost variation between a developer who uses AI for occasional autocomplete and a developer running multi-hour agentic sessions daily. Those two users should not pay the same price, and increasingly, they will not.
The emerging model across the industry looks like a hybrid: a base subscription fee for access and security, plus usage-based pricing for the compute-intensive capabilities. GitHub Copilot’s premium request structure is an early version of this. Cursor’s compute credits are another. Claude’s tiered plans with session limits are a blunter version of the same idea.
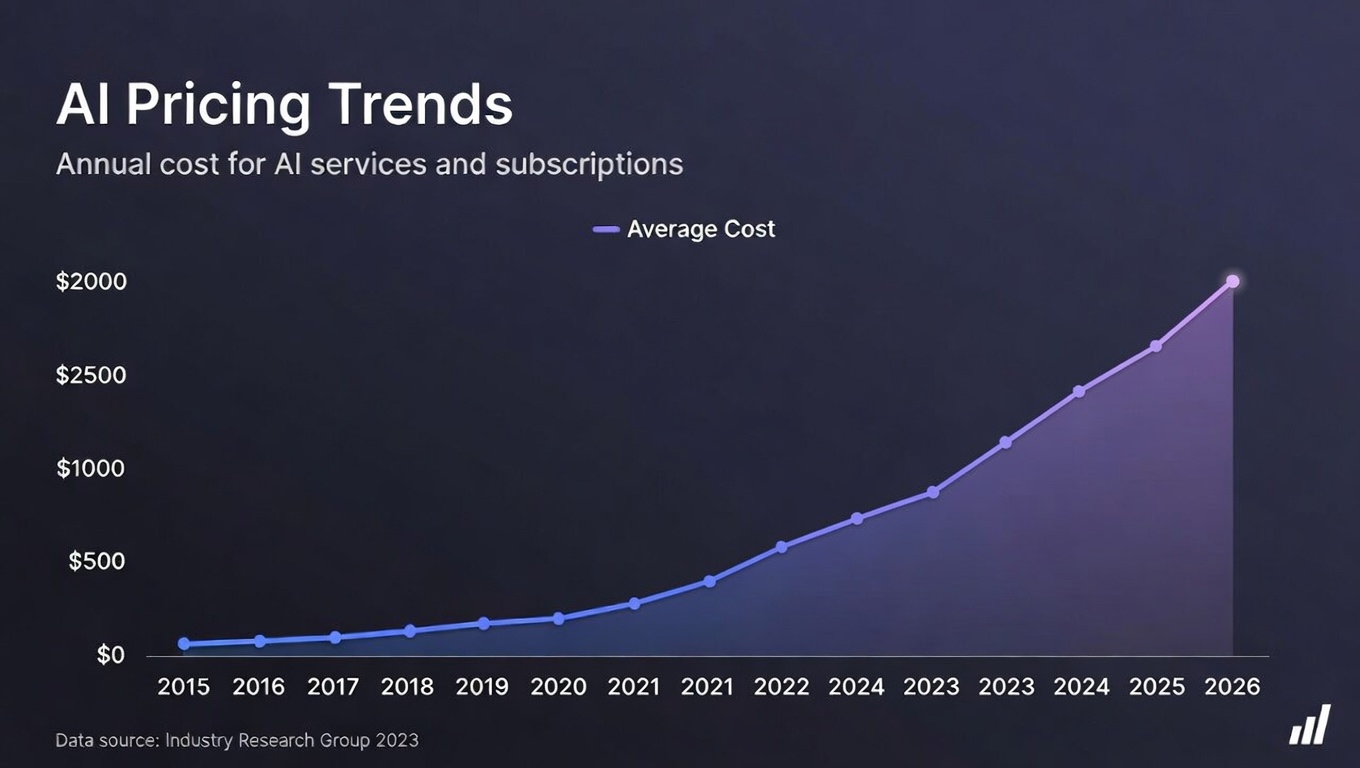
The outcome-based pricing model that some analysts are pointing to as the “gold standard” would charge developers not for tokens consumed but for tasks completed. This would require AI companies to have enough confidence in their models’ success rates to price on outcomes rather than inputs. We are not there yet. The model reliability and task completion rates are not consistent enough to support outcome pricing at scale, though it is a direction the industry is watching.
For developers building businesses on top of these tools, or developers whose productivity gains have become structural parts of their workflows, the shift to honest compute pricing requires a recalibration. The token efficiency guide we published covers practical approaches to managing costs under the new economics. The core insight is that the techniques that felt optional during the subsidy era are now necessary for sustainable usage.
What You Should Actually Do Right Now
The people getting hurt worst by usage limit crackdowns are the ones who built workflows during the subsidy period and have not adjusted to the new cost structure. Here is a practical response:
Audit your actual usage pattern. Are you an agentic-heavy user or a conversational-heavy user? If you are running complex multi-step tasks that used to feel like agentic magic, you are in the highest-cost usage category. Your plan was likely not priced for you.
Match the plan to the workflow. Anthropic’s Max plans are sized for different usage rates than Pro. Cursor’s compute credit system means the headline subscription price is not the accurate cost for heavy users. Review what you are actually consuming, not what the plan nominally offers.
Time-shift intensive work. For Claude specifically, peak hours (5 AM to 11 AM PT weekdays) burn limits faster. If your work schedule allows, moving agentic-heavy sessions to off-peak or weekend windows extends your effective quota meaningfully.
Diversify your toolchain. Depending on a single AI provider for your entire workflow creates an ecosystem risk. Developers who had adopted Kimi as a cost-effective alternative to Claude had a buffer when Claude’s limits tightened. Running different tools for different task types spreads both cost and risk.
Rethink context management. The biggest driver of unexpected limit consumption is accumulated context in long sessions. Starting fresh sessions more frequently for unrelated tasks, keeping system prompts lean, and using existing context management features aggressively reduces consumption more than most developers expect.
Build cost awareness into your development process. The parallel to cloud compute costs is apt. Developers who went through the transition from on-premise infrastructure to AWS or GCP had to learn that every operation has a cost you can see on an invoice. AI compute is going through the same transition. Treat it like cloud spend: monitor it, optimize it, and budget for it.
The Dependency Problem Nobody Wants to Fully Reckon With
The uncomfortable subtext of the limit crackdown story is that a lot of developers and teams have built genuine functional dependencies on AI tools that are now repricing.
This is not catastrophic. These tools still deliver value at higher price points than the subsidy era implied. What has changed is the baseline assumption. If you built a workflow assuming a certain level of AI capability at a certain cost, and that cost is now higher or that capability is now rationed, you have to honestly evaluate whether the ROI still holds.
For most developers doing serious work, it probably does hold. The productivity gains from working with capable AI tools survive price increases to a point. The question is where that point is, and whether the industry reaches it before infrastructure catches up enough to bring prices back down.
There are reasons for optimism on the long horizon. Model efficiency has improved substantially over time. The compute required to run a given level of capability has fallen as models have been optimized. If that trend continues, today’s frontier-level capabilities become cheaper over time even without infrastructure expansion. The GPU supply chain will eventually normalize. Energy constraints will be solved or designed around.
The current period is the painful middle: demand has outrun infrastructure, subsidy-era pricing is ending, and the new equilibrium has not been reached yet. Developers who understand that are positioned to navigate it. Those expecting a return to the open-tap experience of 2024 and early 2025 are likely to be frustrated.
The golden age of unlimited AI might genuinely be over. What replaces it is probably better on a long enough timeline. It is just not free anymore.
Pricing and limit information cited reflects conditions as of April 2026. Specific thresholds change frequently. Verify current terms directly with Anthropic, Google, Moonshot AI, Cursor, and GitHub before making tool or plan decisions.