When you store data in a distributed system, you face a fundamental choice. Do you require that all copies of the data agree at all times? This ensures correctness but limits availability and performance. Or do you allow temporary divergence between copies, accepting that they will eventually agree? This improves availability and performance but complicates application logic.
This is the consistency trade-off. It is not a technical detail to be delegated to the database administrator. It is an architectural decision that affects your application’s behavior, your user experience, and your business logic. A banking system that shows different balances depending on which ATM you use is unacceptable. A social media feed that shows slightly different posts to different users for a few seconds is tolerable.
I have built systems at both extremes and many points between. I have seen the confusion that eventual consistency causes in application code and the downtime that strict consistency requirements can create. This guide covers the patterns that work: understanding ACID and BASE, the CAP theorem’s practical implications, read and write quorum patterns for tuning consistency, and matching consistency models to business requirements.
The Consistency Spectrum
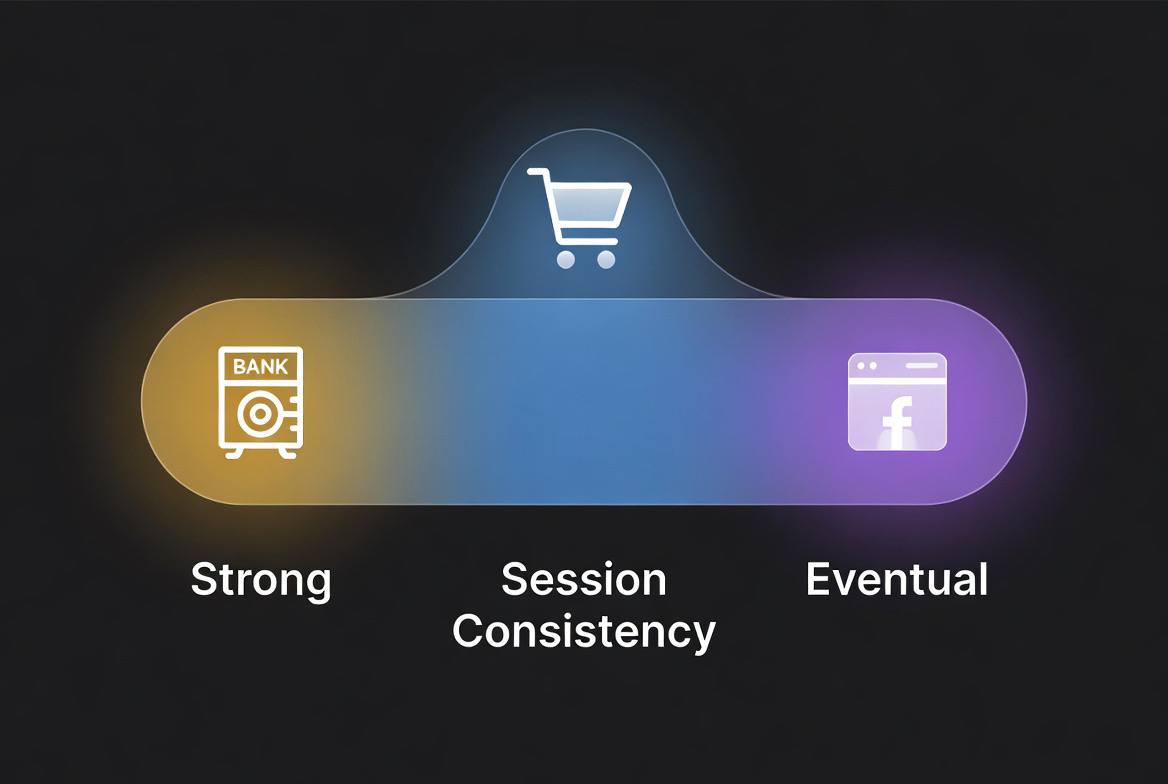
Consistency is not binary. It exists on a spectrum from strong guarantees to weak guarantees, each with different trade-offs.
Strong Consistency: All reads see the most recent write. The system behaves as if there is only one copy of the data.
Eventual Consistency: Reads may see stale data. If no new writes occur, all copies eventually converge to the same value.
Between these extremes exist intermediate models: causal consistency, session consistency, monotonic reads, read-your-writes consistency.
ACID: Strong Consistency in Practice
ACID (Atomicity, Consistency, Isolation, Durability) describes the guarantees provided by traditional relational databases.
Atomicity
A transaction is all-or-nothing. Either all operations complete successfully, or none do. There is no partial completion.
Example: A funds transfer debits one account and credits another. With atomicity, both operations happen, or neither happens. You cannot have the debit without the credit or vice versa.
Consistency
Transactions bring the database from one valid state to another. All integrity constraints and business rules are maintained.
Note: This is different from the “consistency” in CAP theorem. ACID consistency refers to application-level invariants (foreign keys, check constraints). CAP consistency refers to all nodes agreeing on the same data.
Isolation
Concurrent transactions do not interfere with each other. Each transaction executes as if it were the only one running.
Isolation levels:
- Read Uncommitted: Transactions see uncommitted changes from others. Fastest, least safe.
- Read Committed: Transactions see only committed changes. Default in PostgreSQL.
- Repeatable Read: A transaction sees the same data if it reads twice. Prevents non-repeatable reads.
- Serializable: Transactions are completely isolated as if they ran sequentially. Highest safety, lowest concurrency.
Practical isolation:
-- Default (Read Committed)
BEGIN;
SELECT balance FROM accounts WHERE id = 1; -- Sees committed data
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
COMMIT;
-- Serializable (for critical operations)
BEGIN ISOLATION LEVEL SERIALIZABLE;
SELECT balance FROM accounts WHERE id = 1;
-- Other transactions cannot modify this row until we commit
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
COMMIT;Durability
Once a transaction commits, it persists even if the system crashes immediately after.
Implementation: Write-ahead logging (WAL). Changes are written to a log before being applied to the database. After a crash, the log is replayed to recover committed transactions.
BASE: Accepting Weak Consistency
BASE (Basically Available, Soft state, Eventual consistency) describes the approach of distributed NoSQL systems.
Basically Available
The system remains operational for reads and writes, even during failures. This contrasts with ACID systems that may reject operations to maintain consistency.
Soft State
The state of the system can change without external input. This refers to background processes like replication and read repair that modify data without explicit user operations.
Eventual Consistency
If no new updates are made, eventually all replicas will converge to the same value. “Eventually” could be milliseconds or hours depending on the system.
Example: You update your profile picture. Your friend sees the old picture for a few seconds, then sees the new one. The system was inconsistent temporarily, then became consistent.
The CAP Theorem
CAP theorem states that in a distributed system with network partitions, you can have at most two of:
- Consistency: All nodes see the same data at the same time
- Availability: Every request receives a response (success or failure)
- Partition Tolerance: The system continues to operate despite network partitions
The Practical Reality
Network partitions happen. They are a fact of distributed systems. Therefore, the real choice is between:
CP systems: Sacrifice availability for consistency during partitions. If nodes cannot communicate, some nodes refuse requests to prevent divergence.
AP systems: Sacrifice consistency for availability during partitions. All nodes continue accepting requests, accepting that they may diverge and need reconciliation later.
Examples
CP Systems:
- Traditional relational databases with synchronous replication
- etcd, ZooKeeper (consensus systems)
- HBase with strong consistency settings
AP Systems:
- Cassandra with eventual consistency
- DynamoDB (default settings)
- Riak
- DNS (the canonical eventual consistency example)
PACELC: Extending CAP
PACELC adds nuance: if there is a Partition, choose between Availability and Consistency; Else, choose between Latency and Consistency.
Even without partitions, you face a latency-consistency trade-off. Synchronous replication to all nodes adds latency. Asynchronous replication is faster but provides weaker consistency.
Consistency Models in Detail
Linearizability (Strong Consistency)
Linearizability is the strongest consistency model. Operations appear to execute atomically at a single point in time between their invocation and response.
Guarantees:
- Every read sees the most recent write
- All operations appear to happen in a total order
- If operation A completes before operation B begins, A appears before B
Cost: Requires coordination between nodes. Adds latency. Reduces availability during partitions.
Use cases: Financial ledgers, inventory management, anything where stale reads are unacceptable.
Sequential Consistency
Operations appear to execute in some sequential order that respects the order of operations on each individual node.
Weaker than linearizability but still strong. Allows reordering of operations from different nodes as long as each node’s own operations stay in order.
Example: If Node A writes X then Y, and Node B reads Y then X, that is acceptable under sequential consistency (different order than real-time) but not under linearizability.
Causal Consistency
If operation A causally influences operation B (A happens before B, and B knows about A), then all nodes see A before B. Concurrent, unrelated operations may be seen in different orders.
Implementation: Vector clocks or version vectors track causality.
Use case: Collaborative editing (Google Docs). Your edits must appear in order to you, but concurrent edits by others may be ordered differently.
Session Consistency
Consistency guarantees apply within a session (a sequence of operations by one client). A client sees its own writes immediately, even if other clients see stale data.
Example: You post a comment. You see it immediately. Other users may see it after a delay.
Implementation: Route reads from the same replica that handled the write, or use sticky sessions.
Read-Your-Writes Consistency
A client that writes a value will always read that value or a later value, never an earlier one.
Subset of session consistency. Fundamental for user experience: users must see their own actions reflected.
Monotonic Reads
If a client reads a value, subsequent reads will not see earlier values. You cannot “go back in time.”
Example: You see a post with 10 comments. You refresh and see 8 comments. This violates monotonic reads. You should see 10 or more, never fewer.
Eventual Consistency (Weakest)
With no new updates, all replicas eventually converge. No guarantees about what you see before convergence.
Acceptable when: Temporary inconsistency does not harm the business. Social media feeds, analytics dashboards, recommendation engines.
Quorum-Based Consistency
Distributed databases often use quorum mechanisms to balance consistency and availability.
Read and Write Quorums
In a system with N replicas:
- Write quorum (W): Number of replicas that must acknowledge a write
- Read quorum (R): Number of replicas that must respond to a read
Strong consistency: W + R > N
This ensures any read quorum and write quorum overlap. The read will include at least one replica that has the latest write.
Examples:
- N=3, W=2, R=2: W+R=4 > 3. Strong consistency. Writes acknowledged by 2, reads from 2 (must overlap).
- N=3, W=1, R=3: W+R=4 > 3. Strong consistency. Fast writes, slow reads.
- N=3, W=1, R=1: W+R=2 < 3. Eventual consistency. Fastest, but may read stale data.
Dynamo-Style Quorum (Sloppy Quorum)
Cassandra and DynamoDB use a relaxed quorum:
- Write sent to N nodes (where N is replication factor)
- Wait for W acknowledgments
- Read from R nodes, return most recent value
If nodes are unavailable, the system may write to alternative nodes and reconcile later (hinted handoff).
Tunable Consistency
Many systems allow per-operation consistency:
# Cassandra consistency levels
from cassandra import ConsistencyLevel
# Strong consistency for payment
session.execute(
payment_query,
consistency_level=ConsistencyLevel.QUORUM # W+R > N
)
# Eventual consistency for analytics
session.execute(
analytics_query,
consistency_level=ConsistencyLevel.ONE # Fast, may be stale
)Consistency in Practice: Implementation Patterns
Optimistic Concurrency Control
Allow conflicts to occur, detect them, and resolve them.
Implementation: Version numbers or timestamps. Every update includes the version being modified. If the version has changed since read, the update fails.
-- Table with version column
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
content TEXT,
version INT DEFAULT 1
);
-- Update with version check
UPDATE documents
SET content = 'new content', version = version + 1
WHERE id = 1 AND version = 5; -- Expected version
-- Check if update succeeded
IF rows_affected = 0:
raise ConflictError("Document modified by another process")Use case: Collaborative editing, inventory management where conflicts are rare.
Pessimistic Concurrency Control
Prevent conflicts by locking data during access.
Implementation: Database locks, distributed locks (Redis, ZooKeeper).
# Distributed lock with Redis
import redis
import time
r = redis.Redis()
lock_key = "lock:document:123"
lock_timeout = 30 # seconds
# Acquire lock
if r.set(lock_key, "locked", nx=True, ex=lock_timeout):
try:
# Critical section: only one process can execute this
document = read_document(123)
document.content = update_content(document)
write_document(document)
finally:
# Release lock
r.delete(lock_key)
else:
raise LockAcquisitionError("Document is being edited by another user")Use case: Financial transactions, resource allocation where conflicts are common and expensive.
Conflict-Free Replicated Data Types (CRDTs)
Data structures designed such that concurrent modifications can be merged automatically without conflict resolution.
Types:
- G-Counter: Increment-only counter. Merge takes maximum of replicas.
- G-Set: Grow-only set. Merge is set union.
- LWW-Element-Set: Last-write-wins element set. Timestamps determine winner.
- OR-Set: Observed-remove set. Removes only affect elements the replica has seen.
Use case: Collaborative editing (where multiple users may edit simultaneously), distributed counters, shopping carts.
Vector Clocks
Track causality in distributed systems. Each node maintains a counter. When nodes communicate, they exchange and update their clocks.
Conflict detection: If vector clocks are incomparable (neither is greater than or equal to the other), operations are concurrent and conflict.
Use case: Version control (Git uses a form of this), document stores detecting concurrent modifications.
Read Repair and Anti-Entropy
Eventually consistent systems need mechanisms to detect and repair divergence.
Read Repair
When a read detects inconsistent replicas, repair the divergent replicas in the background.
Process:
- Read from R replicas
- Compare values
- If values differ, identify the most recent
- Write the correct value back to out-of-date replicas
Example: Cassandra reads from 3 replicas. Two return value A (timestamp t1), one returns value B (timestamp t0). The system returns A to the client and writes A to the replica with B.
Anti-Entropy Repair
Background process that compares and reconciles all data between replicas, not just data being read.
Implementation: Merkle trees (hash trees) allow efficient comparison of large datasets. If root hashes differ, compare children to find differing segments.
Example: Cassandra runs nodetool repair to synchronize replicas.
Choosing Consistency for Your Use Case
Match consistency requirements to business needs.
Financial Transactions
Requirement: Strong consistency. No stale reads. No lost updates.
Implementation: ACID transactions with serializable isolation. Synchronous replication. Consensus systems for distributed coordination.
Example: Bank transfer must debit one account and credit another atomically. All users must see the same balance.
E-Commerce Inventory
Requirement: Bounded staleness or strong consistency. Overselling is bad, but brief inconsistency may be acceptable.
Implementation: Optimistic locking with version numbers. Reserve inventory during checkout with short TTL.
Example: Two users attempt to buy the last item. First succeeds, second gets “out of stock” even if they saw “in stock” seconds ago.
User Profiles
Requirement: Session consistency minimum. User sees their own updates immediately.
Implementation: Sticky sessions or read-after-write consistency.
Example: User updates profile picture. They see the new picture immediately. Friends see the old picture for a few seconds.
Analytics Dashboard
Requirement: Eventual consistency acceptable. Staleness of minutes or hours is fine.
Implementation: Async aggregation pipelines, cached results, eventual consistency database.
Example: Dashboard shows sales data from 15 minutes ago. Real-time is not necessary.
Social Media Feed
Requirement: Eventual consistency. Different users seeing slightly different feeds is acceptable.
Implementation: Asynchronous fan-out. Cache heavily. Prioritize availability over consistency.
Example: Two users refresh at the same time. User A sees post X, User B does not yet. Both are acceptable experiences.
Implementation Examples
PostgreSQL Synchronous Replication
For strong consistency across PostgreSQL replicas:
-- Primary configuration
synchronous_commit = remote_apply # Wait for replica to apply
synchronous_standby_names = 'replica1, replica2'With this configuration, commits wait until the specified replicas have applied the change. Higher latency, stronger consistency.
Cassandra Consistency Levels
from cassandra import ConsistencyLevel
from cassandra.cluster import Cluster
cluster = Cluster(['127.0.0.1'])
session = cluster.connect()
# Write with QUORUM consistency (strong)
session.execute(
"INSERT INTO users (id, name) VALUES (?, ?)",
(user_id, name),
consistency_level=ConsistencyLevel.QUORUM
)
# Read with ONE consistency (fast, possibly stale)
rows = session.execute(
"SELECT * FROM users WHERE id = ?",
(user_id,),
consistency_level=ConsistencyLevel.ONE
)DynamoDB Consistency
import boto3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('users')
# Strongly consistent read
table.get_item(
Key={'user_id': '123'},
ConsistentRead=True # Default is eventually consistent
)
# Eventually consistent read (faster, half the cost)
table.get_item(
Key={'user_id': '123'}
# ConsistentRead=False is default
)Common Pitfalls
Pitfall 1: Assuming Strong Consistency
Using an eventually consistent database but writing application code that assumes immediate consistency. Leads to race conditions and stale data bugs.
Pitfall 2: Ignoring Conflict Resolution
In distributed systems, conflicts happen. Not planning how to resolve them leads to data loss or corruption.
Pitfall 3: One Consistency Level Everywhere
Using the same consistency for all operations. Analytics queries do not need strong consistency. Financial transactions do not tolerate eventual consistency.
Pitfall 4: Not Testing Failure Scenarios
Testing only the happy path. Network partitions and node failures expose consistency bugs that normal testing misses.
Pitfall 5: Over-Engineering for Strong Consistency
Building a complex consensus system when eventual consistency would suffice. Wastes development time and harms performance.
Pitfall 6: Ignoring Clock Synchronization
Using timestamps for conflict resolution without synchronized clocks. Clock skew causes incorrect conflict resolution.
Conclusion
Consistency is not a boolean choice. It is a spectrum of trade-offs between correctness, availability, and performance. Strong consistency (ACID) ensures correctness at the cost of availability during failures and higher latency. Eventual consistency (BASE) maximizes availability and performance at the cost of temporary divergence.
Match your consistency model to your business requirements. Financial systems need strong consistency. Social feeds tolerate eventual consistency. Most systems have components at different points on the spectrum.
Understand the CAP theorem’s implications for your architecture. During partitions, choose whether to be consistent or available. Design for the failures you can tolerate.
Implement appropriate concurrency control: optimistic for low-contention scenarios, pessimistic for high-contention. Plan for conflict detection and resolution in distributed systems.
Test your consistency guarantees under failure conditions. Network partitions reveal whether your system actually provides the consistency you designed for.
Consistency choices are architectural decisions with long-term consequences. Make them deliberately, with clear understanding of trade-offs, not by default or accident.
Further Reading
- “Designing Data-Intensive Applications” by Martin Kleppmann: Chapters on consistency and replication
- “CAP Twelve Years Later” by Eric Brewer: Updated perspective on the CAP theorem
- Dynamo paper (Amazon): Eventual consistency in practice
- Spanner paper (Google): Strong consistency at global scale
- CRDT research: Conflict-free replicated data types