Multi-region deployments are sold as simple solutions to two problems: serving users globally with low latency, and surviving regional cloud outages. The reality is more complicated. Multi-region architecture introduces consistency challenges, data synchronization complexity, and operational overhead that can produce more incidents than a well-designed single-region setup.
This guide covers when multi-region is the right choice, the architectural patterns for implementing it, the data consistency challenges you will face, and the compliance requirements that sometimes force the decision regardless of technical preference.
When Multi-Region Is Worth It
The business case for multi-region usually falls into one of three categories.
Latency for global users. A 200ms round trip from London to a US-east data center is acceptable for many applications but unacceptable for others. Real-time applications (trading, gaming, video calls), user-interactive applications where perceived responsiveness matters, and any application where 200ms round trips compound across many API calls all benefit from geographic proximity.
Regional failure resilience. AWS us-east-1 has had significant outages. GCP us-central1 has had significant outages. Every cloud region has had significant outages. If your business cannot tolerate downtime during a full regional failure, multi-region is a requirement rather than a nice-to-have.
Data residency compliance. GDPR requires that EU personal data not be transferred outside the EU without adequate protections. Some countries have data localization laws requiring that citizen data remain within national borders. Healthcare regulations in some jurisdictions require data to stay in specific regions. These compliance requirements may force multi-region regardless of the technical trade-offs.
If none of these apply, a highly available single-region deployment (multiple Availability Zones, read replicas, failover) is simpler, cheaper, and less risky.
Architectural Patterns
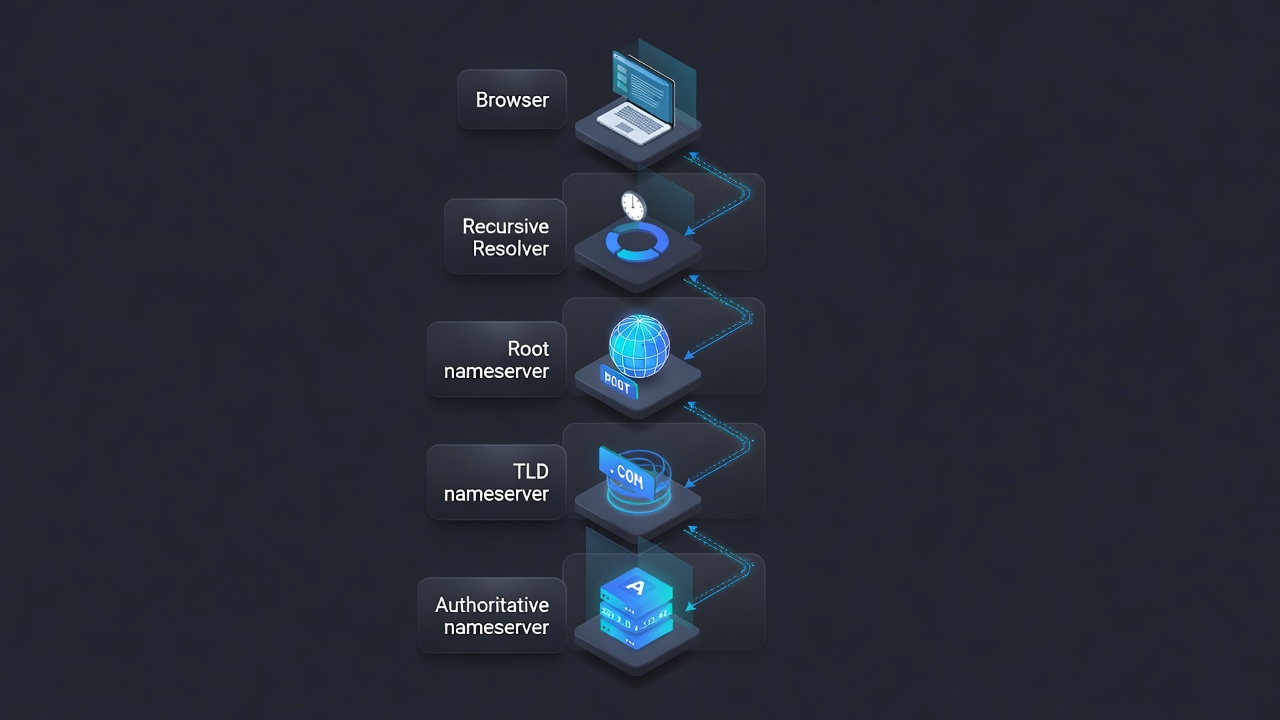
Active-Passive
One region handles all traffic (the active region). The other region maintains a synchronized replica and is ready to accept traffic if the active region fails (the passive region).
 Active-Passive pattern: one region serves all traffic while a second region maintains a hot standby.
Active-Passive pattern: one region serves all traffic while a second region maintains a hot standby.
Traffic flows to Region A. Data is replicated to Region B continuously. If Region A fails, DNS updates to point at Region B. Region B becomes the new active.
Advantages: Simpler to operate. No write consistency challenges. Cheaper than active-active (passive region only needs to handle replica traffic).
Disadvantages: Users far from Region A still experience high latency. Failover requires DNS propagation, which takes time. The passive region’s resources are partially wasted in normal operation.
Failover time: DNS TTL (controlled, can be 60-300 seconds) plus time for Region B to become fully operational. This can range from a few minutes to 30+ minutes depending on application warm-up requirements.
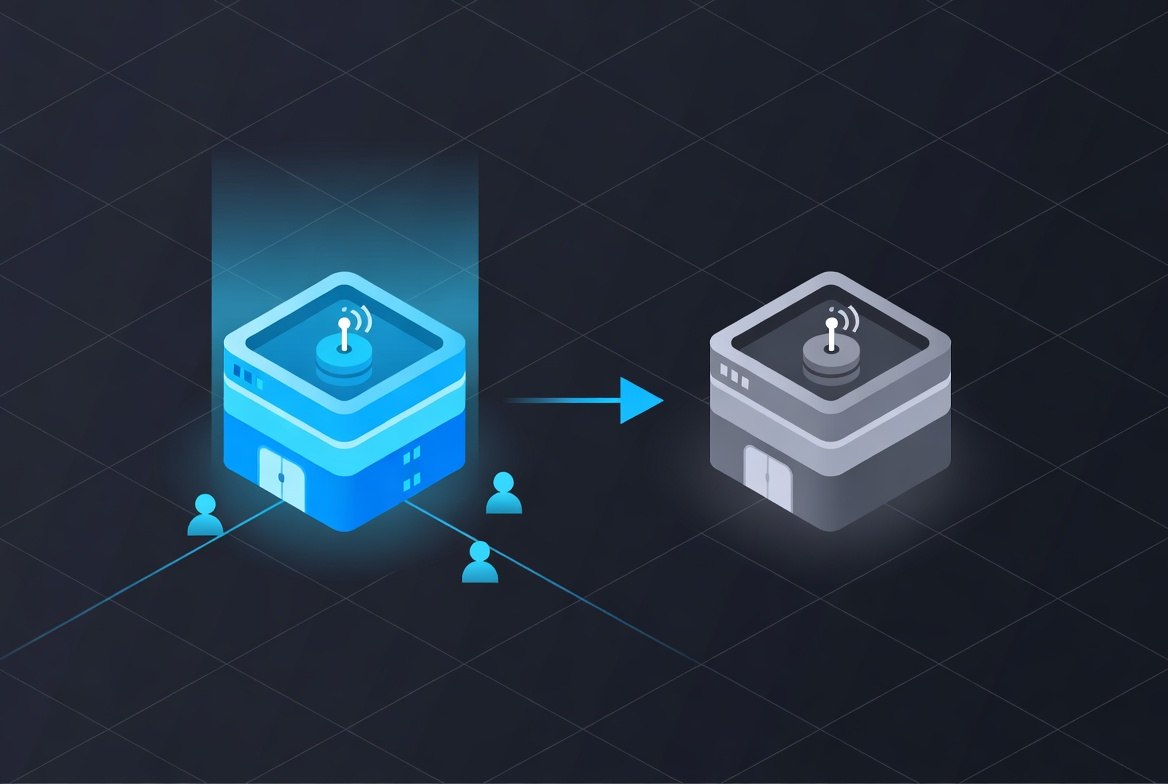
Active-Active
Both regions handle traffic simultaneously. Users are routed to the nearest region. Each region can handle the full request load in isolation.
 Active-Active pattern with GeoDNS routing: users connect to their nearest region while data replicates bidirectionally.
Active-Active pattern with GeoDNS routing: users connect to their nearest region while data replicates bidirectionally.
Advantages: True geographic latency reduction. Survives regional failure without failover (traffic simply routes to the other region). Resources are utilized in both regions.
Disadvantages: Write consistency across regions is a hard problem. If a user in the EU and a user in the US both update the same record simultaneously, which write wins? How does each region know about the other’s writes before serving reads?
Most applications avoid this by restricting writes to one region and handling reads from both. Or they carefully design which data is region-specific versus globally shared.
The Write Consistency Problem
This is where active-active architectures fail in practice. Cross-region database replication introduces latency. An EU database write may take 80-100ms to replicate to the US. During that window, a US read will see stale data.
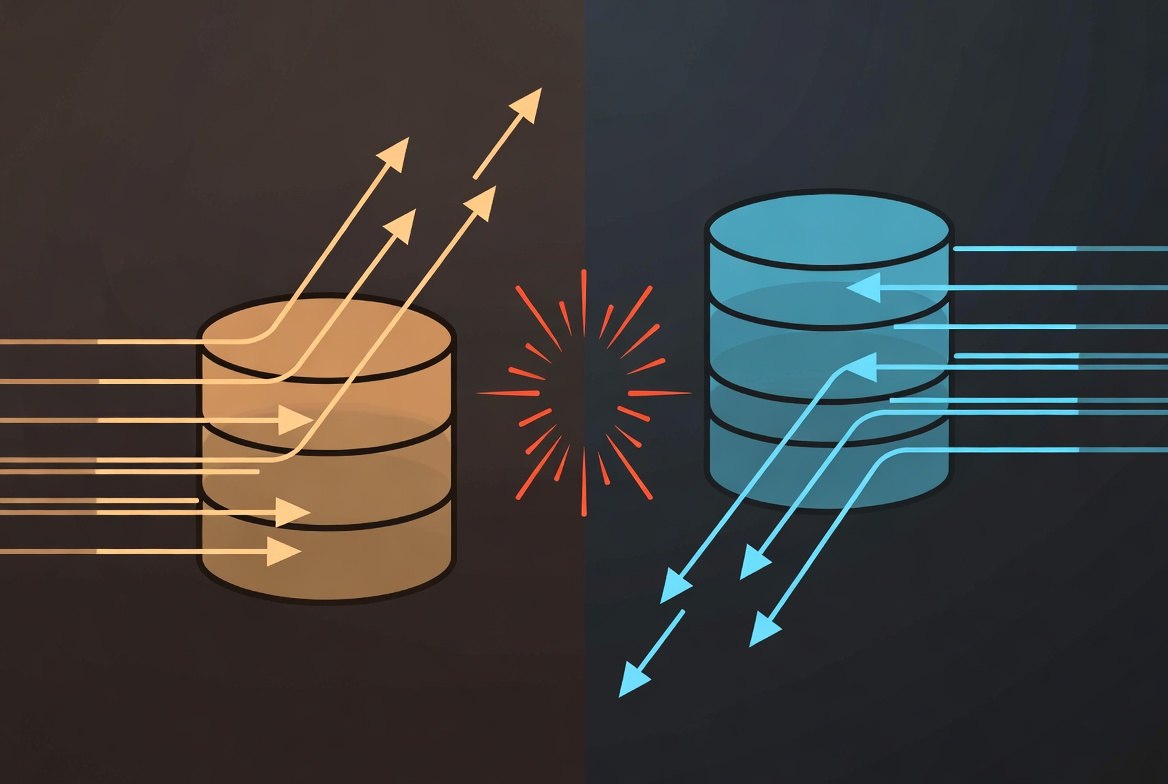 The write consistency problem: a write in one region takes time to replicate, creating a window where other regions see stale data.
The write consistency problem: a write in one region takes time to replicate, creating a window where other regions see stale data.
Acceptable in some cases: User preferences, profile information, content that changes rarely. Stale reads for a few hundred milliseconds are not harmful.
Not acceptable: Financial transactions, inventory levels, booking systems. Stale reads here cause double-spending, overselling, and double-booking.
For writes that require global consistency, there are a few approaches:
Route all writes to a single home region. Users are geographically routed for reads, but writes go to a designated write region. Adds round-trip latency for writes from distant regions.
Conflict-free Replicated Data Types (CRDTs). Data structures designed to merge concurrent writes without conflict. Counters that merge by addition, sets that merge by union. Applicable for specific use cases but not general-purpose databases.
Global databases. AWS Aurora Global Database provides sub-second replication across regions with a primary write region and read replicas globally. CockroachDB and Google Spanner are purpose-built globally distributed databases with strong consistency guarantees at significant cost.
Data Residency and Compliance
Data residency requirements add constraints on top of the architectural choices.
GDPR (EU)
The General Data Protection Regulation restricts transfers of EU personal data to countries without adequate data protection unless specific safeguards are in place. For most SaaS applications serving EU customers, this means EU personal data should be stored and processed in the EU or in countries with adequacy decisions.
Practical implementation:
- Assign EU users to an EU region at signup
- Store all data for EU users in EU infrastructure
- Ensure analytics, logging, and third-party services do not transfer EU user data to non-EU regions
- Document your data flows to demonstrate compliance
// Assign region based on user location at signup
function assignUserRegion(signupCountry) {
const euCountries = new Set([
'AT', 'BE', 'BG', 'HR', 'CY', 'CZ', 'DK', 'EE', 'FI', 'FR',
'DE', 'GR', 'HU', 'IE', 'IT', 'LV', 'LT', 'LU', 'MT', 'NL',
'PL', 'PT', 'RO', 'SK', 'SI', 'ES', 'SE'
]);
if (euCountries.has(signupCountry)) {
return 'eu-west-1';
}
return 'us-east-1';
}Data Localization Laws
Some countries (Russia, China, India, Brazil) have data localization requirements mandating that certain categories of data (personal data, financial records, health records) be stored on servers physically located within the country. Serving these markets may require separate regional deployments.
Before building multi-region infrastructure for compliance, consult with legal counsel who is current on the specific requirements for your data categories and target markets. Regulations change and their interpretation varies.
Traffic Routing
Getting users to the right region requires DNS-level routing.
GeoDNS
DNS responds with different IP addresses based on the geographic location of the DNS resolver making the query. A resolver in Frankfurt gets the EU region IP. A resolver in Virginia gets the US region IP.
AWS Route 53 geolocation routing supports this natively. Cloudflare Load Balancing with proximity steering provides similar functionality with Cloudflare’s network.
GeoDNS routing is approximate because DNS resolver location does not always match user location. A user in Germany might use Google’s 8.8.8.8 resolver, which is located in the US. Route 53 geolocation routing uses resolver IP location, not the client IP. For more precise routing, use a CDN or anycast network that routes by client IP.
Latency-Based Routing
Route 53 latency-based routing measures actual network latency from AWS regions to DNS resolvers and routes to the region with the lowest measured latency, regardless of geographic proximity. This is often more accurate than pure geolocation.
Anycast
Large CDNs and traffic networks use anycast routing, where the same IP address is announced from multiple geographic locations. BGP routes each user’s packets to the nearest network node that announces that IP. This provides genuinely client-IP-based routing without the approximations of DNS-based approaches.
Cloudflare, Fastly, and AWS CloudFront all use anycast for their networks. Placing your application behind one of these services provides geographic routing without managing your own multi-region infrastructure for the traffic layer.
Deploying to Multiple Regions
Infrastructure as code makes multi-region deployment manageable.
Terraform with Multiple Providers
# providers.tf
provider "aws" {
alias = "us_east"
region = "us-east-1"
}
provider "aws" {
alias = "eu_west"
region = "eu-west-1"
}
# modules/app_region/main.tf - reusable module for one region's stack
module "app_us_east" {
source = "./modules/app_region"
providers = {
aws = aws.us_east
}
region_name = "us-east"
db_snapshot_id = var.us_snapshot_id
}
module "app_eu_west" {
source = "./modules/app_region"
providers = {
aws = aws.eu_west
}
region_name = "eu-west"
db_snapshot_id = var.eu_snapshot_id
}The reusable module creates identical infrastructure stacks in each region. Changes to the module deploy consistently to all regions.
Testing Regional Failover
Failover testing is as important as restore testing for backups. The steps that work in a planned drill work under pressure. The steps that have never been tested will fail at 3 AM.
Test steps for active-passive failover:
- Verify the passive region is synchronized and healthy before the test.
- Simulate region failure by blocking traffic to the active region at the load balancer level (do not actually take down the region).
- Execute the documented failover procedure: update DNS records, confirm replication has caught up, verify the passive region can accept writes.
- Measure the actual failover time.
- Verify the application functions correctly in the now-active passive region.
- Fail back to the original active region and measure that time too.
- Document everything that did not go as expected.
Run this drill at least twice a year as part of your CI/CD pipeline testing strategy. The first time reveals problems in the runbook. Subsequent runs build team confidence and muscle memory.
Cost Considerations
Multi-region infrastructure roughly doubles your baseline infrastructure cost. Two database clusters. Two application server fleets. Cross-region data transfer charges (which are often underestimated).
AWS cross-region data transfer is currently priced at $0.02 per GB. An application transferring 10TB of data per month between regions pays $200 per month just for transfer. At 100TB, that is $2,000 per month. Understand your data transfer volume before committing to an architecture that depends on high-bandwidth cross-region replication.
For applications that do not yet need full multi-region infrastructure, caching strategies and API gateway patterns can provide significant latency improvements without the complexity of full multi-region deployment. Consider intermediate approaches: active-passive with a warm standby in a second region (lower cost than fully active), or relying on your cloud provider’s managed services for geographic redundancy without managing a full second region yourself.
The architecture question is always: what level of availability and geographic performance does the business actually require, and what is the cost of achieving it? This ties back to broader infrastructure decisions like load balancing and disaster recovery planning.
 The cost-complexity spectrum: start simple, add redundancy only when the data demands it.
The cost-complexity spectrum: start simple, add redundancy only when the data demands it.
Multi-region is often the right answer. It is rarely the starting point.
Conclusion
Multi-region architecture is a powerful tool when the business case is clear. It reduces latency for global users, provides resilience against regional failures, and enables compliance with data residency requirements. But it is not free. The complexity of cross-region consistency, the operational overhead of managing multiple deployments, and the cost of duplicated infrastructure all demand careful evaluation.
Start with a highly available single-region deployment. Add read replicas and CDN caching. Measure your actual latency and availability requirements. When the data shows that single-region is insufficient, then invest in multi-region with a clear understanding of the trade-offs. The best multi-region architecture is the one you understand well enough to operate at 3 AM when something breaks.