Most small business sales teams score leads the same way: gut feeling and whoever called last. Sales reps mentally categorize inbound leads as “hot,” “worth a follow-up,” or “probably not going anywhere”, based on instinct shaped by experience. Sometimes that intuition is accurate. More often, it means reps spend the same amount of time on leads with a 2% close probability as leads with a 40% close probability.
AI-powered lead scoring changes this. Instead of gut feeling, every lead gets a score based on the same objective signals: company size, industry, engagement behavior, how they found you, what pages they visited, whether they downloaded your pricing guide. The system continuously updates scores as new signals arrive and improves its accuracy over time as it learns which combinations of signals actually predict closed deals.
I have implemented this for several small business clients over the past five years. The results are consistent: sales teams spend more time on better leads, close rates improve, and the feedback loop means the system keeps getting better as long as someone maintains the outcome data. One client saw close rates rise from 8% to 14% within two quarters after routing A-grade leads to senior reps first.
If you are also thinking about how AI fits into your broader sales stack, our guide to choosing a CRM for small business covers the foundation that scoring sits on top of.
Why Manual Scoring Fails at Scale
Manual lead scoring breaks down as lead volume grows. A rep who handles 10 leads per week can genuinely evaluate each one. A rep handling 50 leads per week starts cutting corners on evaluation, which usually means defaulting to whoever contacted them most recently or whoever seems easiest to close, not whoever is most likely to become a valuable customer.
There is also the consistency problem. Different reps apply different criteria, and the same rep applies different criteria on different days depending on their pipeline pressure. A consistent scoring model eliminates both issues.
The secondary benefit is documentation. When every lead score comes from an explicit model, you can audit decisions, explain to marketing why certain lead sources produce low-quality leads, and make data-driven arguments for budget allocation.
What Data You Actually Need
Lead scoring with AI does not require a data warehouse. The minimum viable dataset for a small business is manageable.
Firmographic data
Information about the lead’s company:
- Company size (employees or revenue): More employees typically correlates with larger deal size and longer sales cycles
- Industry: Some industries match your product better than others
- Geography: If you serve specific regions, location matters
- Technology stack: For B2B tech products, knowing what tools a company uses predicts fit (enrichment services like Clearbit or Apollo.io can provide this via API)
- Company age: Startups and established companies often have different needs and budgets
Behavioral data
What the lead has actually done:
- Pages visited: Pricing page visits are high-intent; blog post visits are low-intent
- Content downloaded: Case studies and ROI calculators signal purchase consideration; top-of-funnel guides signal early research
- Email engagement: Opens are weak signals; clicks on specific links are stronger
- Demo or trial requests: Strong purchase intent signals
- Return visits: Frequency of engagement matters more than any single visit
- Time on site: Longer sessions suggest genuine interest
AI email automation can feed many of these engagement signals directly into your scoring model without manual data entry.
Lead source
Where the lead came from:
- Paid search vs. organic vs. referral vs. direct
- Which specific campaign or keyword (if available)
- Referred by a customer vs. found independently
Historical outcome data
This is the crucial ingredient most small businesses underinvest in. You need records of which past leads converted to customers and which didn’t, along with the signal data that was available at the time of initial contact.
Without outcome data, you are building a scoring model on assumptions rather than evidence. Start collecting and tagging outcomes in your CRM immediately. Even 3-6 months of clean outcome data is enough to start building a meaningful model.
Building the Scoring Model
There are three approaches, ordered by sophistication.
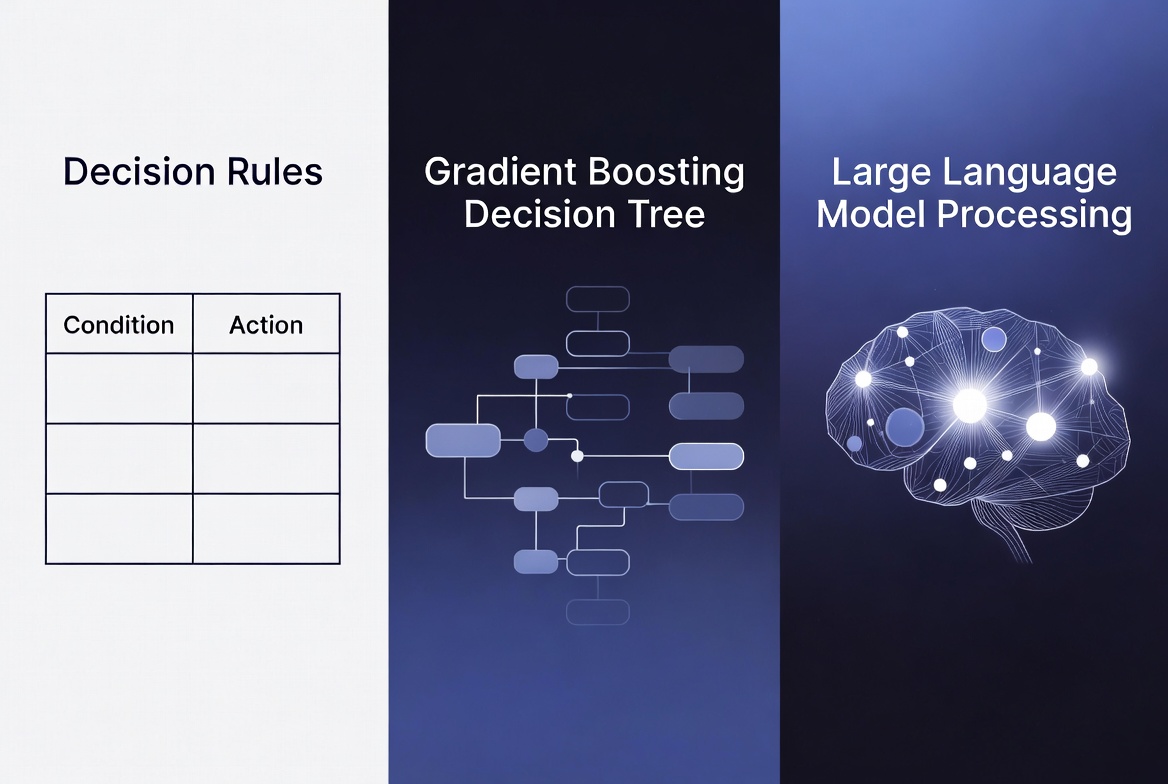
Approach 1: Rule-based scoring (zero ML)
Before you have enough data for machine learning, rule-based scoring using business logic is more accurate than no scoring at all. The idea is simple: assign point values to signals you believe predict conversion, sum them up, and map the total to a grade.
A starting rule set might look like this:
| Signal | Points |
|---|---|
| Requested demo | +40 |
| Visited pricing page | +25 |
| Company size in target range (10-500 employees) | +20 |
| Target industry match | +15 |
| Downloaded case study | +15 |
| High page view count (10+) | +10 |
| Customer referral source | +20 |
| Partner referral source | +15 |
| Organic search source | +8 |
| Paid social source | +5 |
The score is then normalized to a 0-100 scale and mapped to grades: A (75+), B (50-74), C (25-49), D (below 25). This approach is transparent (you can explain every score to a rep), easy to adjust as you learn which signals actually predict conversion, and requires no historical data to start.
Approach 2: Gradient boosting with historical data
Once you have 200+ closed/lost deals with associated lead data, you can train a proper predictive model. Gradient boosting (using XGBoost or LightGBM) outperforms logistic regression on tabular business data and provides feature importance scores to explain what drives predictions.
The pipeline works like this:
- Feature preparation: Encode categorical variables (industry, source, geography), create derived features like an engagement score (weighted sum of page views, email opens, clicks, downloads), and calculate days since first touch.
- Model training: Train a gradient boosting classifier with class balancing (closed-lost deals usually outnumber closed-won). A typical starting configuration uses 100 estimators, max depth of 4, and learning rate of 0.1.
- Evaluation: Monitor ROC-AUC. Anything above 0.70 is usable; above 0.80 is strong for small business data. Review feature importance to confirm the model is learning sensible patterns.
- Prediction: Convert the model’s probability output to a 0-100 score and map to grades, just like the rule-based system.
Approach 3: LLM-based scoring with enrichment
For complex B2B deals where the sales narrative matters as much as the behavioral signals, an LLM can evaluate leads that have been enriched with contextual information. Feed the model a structured prompt containing the lead’s firmographic and behavioral data, your ideal customer profile, and any relevant company news or LinkedIn summaries.
The LLM returns a JSON evaluation with ICP fit score (0-40), intent score (0-40), timing score (0-20), plus key positives, concerns, recommended approach, and talking points. This gives reps actionable context, not just a number.
The LLM approach works best as a supplement to the rule-based or ML model, not a replacement. Use the ML model for high-volume initial triage and the LLM for deeper evaluation of B-grade leads where human review effort is harder to justify.
If you want to refine the prompts that power the LLM layer, our post on the best AI prompts for business owners gives reusable templates.
CRM Integration
Scores need to live in your CRM where sales reps can see and act on them. The implementation depends on which CRM you use.
The CRM choice matters because scoring only works if reps actually see and trust the scores. See our comparison of small business CRM options before you build custom fields.
HubSpot integration
Create three custom contact properties: ai_lead_score (number), ai_lead_grade (string), and ai_score_reasons (multi-line text). Use the HubSpot CRM API to PATCH these properties onto contact records whenever a score is calculated.
Once scores are flowing in, build a HubSpot workflow that triggers on score updates:
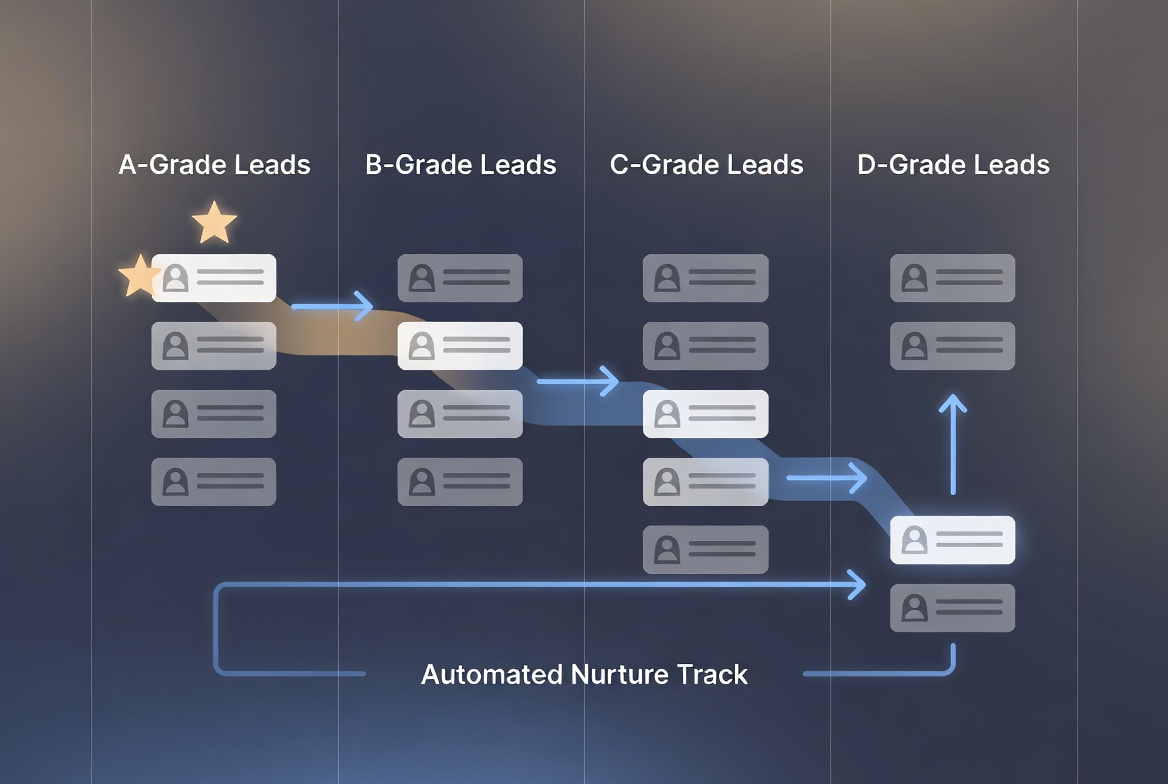
- A-grade leads move to a “Hot” pipeline stage and get immediate rep assignment
- B-grade leads get assigned to the next available rep within 24 hours
- C/D-grade leads enter a long-term nurture sequence
Salesforce integration
The pattern is nearly identical. Create custom fields on the Lead object (for example, AI_Lead_Score__c, AI_Lead_Grade__c). Use the Salesforce REST API or a library like simple-salesforce to update records. Then build Process Builder or Flow automation to route leads based on grade.
Automating score recalculation
Lead scores should update when new signals arrive, not just at the time of initial capture. Set up webhooks or polling for events like page views, email opens, link clicks, form submissions, demo requests, and deal stage changes.
When an event fires:
- Fetch the contact’s current data from the CRM
- Apply the new signal to the lead record
- Recalculate the score using your model
- Write the updated score back to the CRM
- If the grade improved to A, notify the assigned rep immediately
Building the Feedback Loop
A lead scoring system that doesn’t learn from outcomes degrades in value over time. Markets change, product positioning changes, and the signals that predicted conversion six months ago may not be the most predictive signals today.

Capturing outcomes in the CRM
Every closed deal needs to feed back into the scoring system. Set up your CRM so that:
- When a deal closes (won or lost), it automatically records the close date and outcome
- The lead’s score at the time of first contact is preserved alongside the outcome
- A weekly export or webhook triggers a retraining pipeline
The key is capturing the lead data as it existed at first contact, not as it looks today. A lead who visited 50 pages after entering your system is not representative of what you knew when you first scored them.
Scheduled retraining
Run retraining weekly or monthly via cron, a scheduled cloud function, or your orchestration tool of choice. The pipeline should:
- Pull all deals closed in the last 6-12 months
- Fetch the first-contact snapshot for each lead
- Train a new model only if you have at least 200 records
- Compare the new model’s ROC-AUC to the current model’s performance
- Deploy the new model only if it exceeds a threshold (for example, AUC > 0.65) and beats the previous model
- Send a notification with the new model’s performance metrics
Skip retraining when the dataset is too small, and never deploy a model that underperforms the current one. The goal is steady improvement, not constant churn.
Common Implementation Mistakes
Scoring on too few signals: A model with only 3-4 features doesn’t have enough information to be meaningfully predictive. Collect at least 8-10 signals before building a statistical model.
Ignoring deal size: A lead who converts to a $500/month contract and a lead who converts to a $5,000/month contract are both “converted,” but they’re not equally valuable. Train separate models or add expected deal value as a scoring component.
Not communicating score meaning to reps: If reps don’t understand what an A grade means (and doesn’t mean), they’ll ignore the scores or misuse them. Write a one-page explainer: what signals drive the score, what A/B/C/D grades mean in terms of recommended actions, and what to do when the score seems wrong.
Skipping the feedback loop: A model that never retrains becomes stale. Build the outcome collection and retraining pipeline from the start, even if you run it manually at first.
Over-relying on behavioral signals: Page views and email opens are owned by marketing, but close rate is owned by sales. A lead can have perfect behavioral engagement and still fail to close because of budget, timing, or fit issues. Behavioral signals are leading indicators, not certainties.
The teams that get the most value from lead scoring use it as a prioritization tool, not a filter. Every lead still gets some level of outreach. High-scoring leads get outreach first, get more personal attention, and get the senior rep. Lower-scoring leads get automated nurture sequences. The model decides the distribution of human attention, not who gets ignored entirely.
Conclusion
AI lead scoring is not a magic ranking system. It is a prioritization layer that makes your existing sales process more efficient and more consistent. Start with rule-based scoring, collect clean outcome data, graduate to a statistical model when you have enough deals, and keep retraining as your market evolves.
The same principle applies to other AI systems in your business. Our guide to building an AI customer support agent shows how a similar feedback loop turns chatbot transcripts into better responses. Whether you are scoring leads or automating support, the model improves only when you close the loop between prediction and outcome.